前言:
本文会持续更新,同时也会对之前更新的内容做补充和修改,欢迎指正
Go语言
Go语言类似于c语言一样是编译型的语言,编译过程为将认为可读懂的代码转换为01二进制送给机器进行编译
对Go语言代码的基本认识

Go语言语法
在命令行中对我们所写的Go语言代码进行编译为exe可执行文件:
go build //将当前所写的代码编译为可执行的exe文件
go run //类似于python脚本的执行方式执行当前Go语言代码
go build -o wdnmd //将当前Go语言代码编译为文件名为wdnmd的exe可执行文件其中go build语法如果我们想要在不是Go语言代码所在文件中将其编译语法如下
go build //想要执行的Go语言代码在GOPATH/src之后的位置例如如果我想要执行在src文件夹中1文件夹中的Go语言代码语法为:
go build 1go insatll //此命令为先将当前的Go语言代码进行编译为可执行文件再将其放在GOPATH/bin目录下Go语言中的变量声明
普通变量
Go语言中可以在函数外进行变量的声明对于变量的声明语句
var name string //声明一个名字为name的string型的变量可以是全局变量也可以是局部变量
var age int //声明一个名字为age的int型变量可以是全局变量也可以是局部变量对于多个变量可以进行以下的声明
var(
a string
b int
c bool
)全局变量在声明且被赋值后如果没有对其进行利用的话Go语言会出现报错,同时非全局变量在被声明后如果未被利用(不对其进行赋值也会报错)也会报错,Go语言规定一个被赋值的变量必须被利用否则会报错,如果只是对一个变量进行了声明没有进行赋值则不会被报错。
var name string = "lsp" //对变量进行声明并且赋值
var name = "lsp" //对变量直接进行赋值,Go语言会对其进行类型推测
name := "lsp" //只能用于函数中的局部变量的赋值匿名变量
Go语言中定义了一个匿名变量_有时我们对于一个函数的返回值只想接受一个返回值这时就会用到匿名变量,用匿名变量来接收不想收到的变量数据,因为匿名变量不占用内存空间也不会被分配内存所以我们所传输的数据就无了
在同一个作用域中对于同名的变量不能进行二次声明会出现报错
Go语言中的打印函数
fmt.Print(变量名) //类似于python的打印函数
fmt.Print("名字为:%s",name) //类似于c++的打印函数
fmt.Ptintln(变量名) Go语言中的常量
Go语言中的如果想要设置一个无法被改变的量则需要用到const对一个变量进行声明
const age = 18 将age作为一个值为18的常量
const(
age = 18
grade = 16
)
//批量进行常量的声明
const(
n1 = 100
n2
n3
)
//批量进行常量的声明若不做特殊设置则默认n2和n3以及往下的常量值均为n1的值
const(
n1 = iota
n2
n3
)
/*其中n1所赋值的iota在const关键字出现时将被重置为0(const 内部的第一行之前),
const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)
所以n2为1,n3为2*/左移运算符:
1 << (10) //将1左移10为结果为10000000000Go语言中的数字类型
Go 也有基于架构的类型,例如:int、uint 和 uintptr。
| 序号 | 类型和描述 |
|---|---|
| 1 | uint8 无符号 8 位整型 (0 到 255) |
| 2 | uint16 无符号 16 位整型 (0 到 65535) |
| 3 | uint32 无符号 32 位整型 (0 到 4294967295) |
| 4 | uint64 无符号 64 位整型 (0 到 18446744073709551615) |
| 5 | int8 有符号 8 位整型 (-128 到 127) |
| 6 | int16 有符号 16 位整型 (-32768 到 32767) |
| 7 | int32 有符号 32 位整型 (-2147483648 到 2147483647) |
| 8 | int64 有符号 64 位整型 (-9223372036854775808 到 9223372036854775807) |
浮点型
| 序号 | 类型和描述 |
|---|---|
| 1 | float32 IEEE-754 32位浮点型数 |
| 2 | float64 IEEE-754 64位浮点型数 |
| 3 | complex64 32 位实数和虚数 |
| 4 | complex128 64 位实数和虚数 |
其他数字类型
以下列出了其他更多的数字类型:
| 序号 | 类型和描述 |
|---|---|
| 1 | byte 类似 uint8 |
| 2 | rune 类似 int32 |
| 3 | uint 32 或 64 位 |
| 4 | int 与 uint 一样大小 |
| 5 | uintptr 无符号整型,用于存放一个指针 |
补充
Go语言中小数默认是float64类型的,且float32位的数值不能赋值给float64位
对变量的类型进行float32位的声明语法:
num := float32(1.123456) //num变量的数值类型此时为32位Go语言中对于布尔值有较为严格的限制,对于一个变量声明为布尔类型则默认为false,布尔值不能参与运算(与Python不同),且其他数据类型也不能强制转换为布尔类型,布尔类型也无法转换为其他类型
Go语言中的字符串
fmt.Println(len(s1)) //打印s1变量的长度
fmt.Println(name+age) //将name和age两个变量进行拼接输出
ss1=fmt.Sprintf("%s%s",name,age) //将name变量和age变量进行拼接后赋值给ss1变量将一段字符串进行分割
ret := strings.split(s3, "\\") //将一段字符串以\进行分割例如s3的值为:lsp\wdnmd 分割后就为:lsp wdnmd判断字符串中是否含有指定的字符串
fmt.Println(string.Contains(ss,"wd")) //判断ss这个变量中是否含有wd这个字符如果含有则输出true没有则输出false判断字符串是否以指定的字符串结尾/开始
fmt.Println(strings.HasSuffix(ss, "a")) //判断ss变量是否以a结束(返回值为true或false)
fmt.Println(strings.HasPrefix(ss, "a")) //判断ss变量是否以a开始(返回值为true或false)找到某字符串中指定字符串的位置
fmt.Println(strings.Index(ss, "c")) //输出ss变量中字符c第一次出现的位置
fmt.Println(strings.LastIndex(ss, "c")) //输出ss变量中字符c最后一次出现的位置字符串拼接
fmt.Println(strings.Join(ss,"+")) //将ss中的字符串用+好进行拼接if else 语句
Go语言中有着这样的if语句同c语言不同
if age:=19; age>18{
fmt.Println("lsp")
}
else{
fmt.Println("xxs")
}
/*以上语句中同c语言不同的是Go语言可以在if后临时进行变量的声明,
但仅限于这个if语句(此时age变量的作用域仅在if语句这个作用域中)*/for循环
var i=0for ;i<10;i++{
fmt.Println(i)
}
//第一种for循环,省略了初始语句var i=0for i<10{
fmt.Println(i)
i++
}
//第二种for循环将结束语句移至循环体内部for{
语句
}
//死循环可以通过break等退出循环s:= "hello 你好"
for i,v:=range s{
fmt.Printf("%d %c\n",i,v)
}
/*将s这个字符串中每个字符的索引赋值给i字符内容赋值给v进行循环输出
(一般一个中文字符会占用三个空间也就是说在s中的第5-7个空间中储存的是“你”这个字符)*/位运算符
Go 语言支持的位运算符如下表所示。假定 A 为60,B 为13:
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符”&”是双目运算符。 其功能是参与运算的两数各对应的二进位相与。 | (A & B) 结果为 12, 二进制为 0000 1100 |
| | | 按位或运算符”|”是双目运算符。 其功能是参与运算的两数各对应的二进位相或 | (A | B) 结果为 61, 二进制为 0011 1101 |
| ^ | 按位异或运算符”^”是双目运算符。 其功能是参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。 | (A ^ B) 结果为 49, 二进制为 0011 0001 |
| << | 左移运算符”<<”是双目运算符。左移n位就是乘以2的n次方。 其功能把”<<”左边的运算数的各二进位全部左移若干位,由”<<”右边的数指定移动的位数,高位丢弃,低位补0。 | A << 2 结果为 240 ,二进制为 1111 0000 |
| >> | 右移运算符”>>”是双目运算符。右移n位就是除以2的n次方。 其功能是把”>>”左边的运算数的各二进位全部右移若干位,”>>”右边的数指定移动的位数。 | A >> 2 结果为 15 ,二进制为 0000 1111 |
赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,将一个表达式的值赋给一个左值 | C = A + B 将 A + B 表达式结果赋值给 C |
| += | 相加后再赋值 | C += A 等于 C = C + A |
| -= | 相减后再赋值 | C -= A 等于 C = C - A |
| *= | 相乘后再赋值 | C *= A 等于 C = C * A |
| /= | 相除后再赋值 | C /= A 等于 C = C / A |
| %= | 求余后再赋值 | C %= A 等于 C = C % A |
| <<= | 左移后赋值 | C <<= 2 等于 C = C << 2 |
| >>= | 右移后赋值 | C >>= 2 等于 C = C >> 2 |
| &= | 按位与后赋值 | C &= 2 等于 C = C & 2 |
| ^= | 按位异或后赋值 | C ^= 2 等于 C = C ^ 2 |
| |= | 按位或后赋值 | C |= 2 等于 C = C | 2 |
由于Go语言中无法进行对同一变量的再次声明赋值所以赋值的运算目前只能以以上为标准
数组
语法为:
var a1 [3]bool //声明一个长度为3的bool类型的数组对数组进行初始化:
al =[3]bool{true,true,true}
//最简单的初始化
a10 :=[...]int{1,2,3,4,5,6,7,8,9}
//对a10进行初始化,且长度会自动推算
a5 :=[5]int{0:1,4:2}
//第一个空间位置为1,第五个空间位置为2二维套娃式数组:
实现的目标为:[[3,2],[4,5],[6,7]]
语句为:
var a32 [3][2]int //声明三个长度的数组且其中每个数据类型均为含有两个数据空间的数组
a32 = [3][2]int{
[2]int[3,2],
[2]int[4,5],
[2]int[6,7],
}
//输出结果为:[[3,2],[4,5],[6,7]]切片(slice)
由于Go语言中的数组长度有着限制在很多方面存在着限制,所以出现了切片的定义,它相对于数组来说长度没有限制但需要定义类型
var s []int //定义一个int类型的名为s的切片
var s2 []string //定义一个string类型的名为s2的切片切片的初始化
var s [...]int{}
s =[]int{1,2,3}
//定义一个int型的切片并通过手动赋值进行初始化
var s1 []string
s1=[]string{"cnm","wdnmd","wd"}
//定义一个string型的切片并进行初始化其他
fmt.Println(s == nil)
//判断切片是否为空,若为空则返回true不为空则返回false,
//nill相当于一个判断函数会返回布尔值
cap(s)
//返回当前切片的容量(有多少个元素已用)这里解释一下cap函数和len函数的区别:
len函数会统计数组和切片的长度,而cap函数会统计数组和切片的容量(包括不可见的数字)
接下来利用一个例子来解释
arr := []int{2, 3, 5, 7, 11, 13}
sli := arr[1:4]
fmt.Println(sli)
fmt.Println(len(sli))
fmt.Println(cap(sli))这里输出的结果len和cap不一样的原因是len只统计了可见的数字数目即在切片内部的数字,而cap统计了所有的数字即切片的引用源arr数组。
a :=[...]int{1,3,5,7,9}
s :=a[1:4] //取a数组中索引从第0到第3的元素赋值给s切片
s1:=a[:4] //将a数组从开始到第四位赋值给s1切片
s2:=a[4:] //将a数组从第四位到倒数第二位赋值给s3切片
s3:=a[:] //将a数组从开始到倒数第二位赋值给s3切片对一个来自数组的切片我们可以对其进行再次切片,但我们会发现有些切片的容量会不太相同,这里Go语言有了一个定义:切片的容量为底层数组从切片的第一个元素到数组最后的元素数量,例如我们将一个7个元素的数组进行两个切片一个是s :=a[0:4] ,另一个s1:=a[:4],这里两个切片的容量就会不一样了,第一个容量为7,而第二个则为4。
make函数创造切片
s1 := make([]int,5 ,10)
//创造一个长度为5容量为10的int型的切片,
//容量为10表示可以最多进行扩充5个空间(此切片最大占用10 个空间)其中若容量没有做相关的声明则默认与所定义的长度相同
切片的扩容(不超过切片的容量)
我们在定义一个切片的长度通常不会特别长,我们在利用切片时如果超过了切片的长度,可以利用切片的重制来进行切片的扩展,而改变切片长度的过程称之为切片重组 reslicing,具体的用法为:
slice = slice[0:len(slice)+1]但是此机制所加的切片长度有限即我们所定义的切片容量,如果想要一个切片的容量能够自由加长需要用append机制
append函数对切片进行扩容
语法为:
s1 = append(s1 , "wdnmd") //将wndmd字符添加到s1切片中去并调用s1来接收返回值append函数的扩容相当于把现在扩容的切片的内存地址进行了转换,转换到了一个新的内存空间中,因为原本所分配给此切片的内存空间不能放下所扩容后的切片所以此时Go语言会重新分配给此切片一个新的内存大小,同时我们一定要有一个变量来接收append的返回值否则就会报错.
对于利用append函数进行扩容后,对新的切片容量大小的判断:
1.如果新申请的容量大于原来的二倍则最终容量会以你所申请的容量为准。
2.如果原本的切片容量小于1024则最终容量会是原本的二倍
3.如果原本的容量大于1024则最终容量会开始循环增加原来的四分之一,直到最终容量大于等于新申请的容量
4.上边第三步如果最终容量计算溢出则最终容量是新申请的容量
将两个切片进行合并语法:
s1 = append(s1 , ss...)
//将s1切片和ss切片合并然后赋值给s1切片,
//其中ss...表示将ss切片进行拆开然后将拆开后的值添加到s1中copy函数对切片进行复制
语法为:
copy(目标切片 , 源切片)copy函数是将源切片中的数值复制然后将其写入到目标切片中,与我们常见的a1 :[]=a 不同的是copy只是将值复制给了目标切片,而常见的a1 :[]=a这样的语法意思是a1和a所指向的储存地址均为a中所储存的数据地址。
多维切片
和多维数组相似,切片会有自己的二维切片,声明语法为:
//声明一个二维切片
var slice [][]int
//为二维切片赋值
slice = [][]int{{10}, {100, 200}}上方例子中切片具体存储方式如下图:
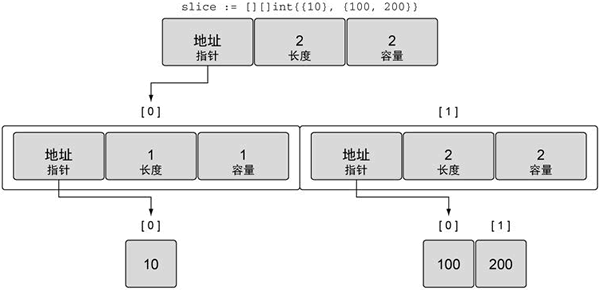
上图引自 http://c.biancheng.net/view/4119.html
如果利用append对此二维切片的第一个元素的切片添加一个数字具体的方法为先将内部的整形的切片即原先10这个数所在整形切片进行扩容,再将新的整型切片赋值给外层切片的第一个元素,当上面代码中的操作完成后,再将切片复制到外层切片的索引为 0 的元素。(我也搞不太懂)
对切片进行元素的删除
由于Go语言中没有对切片中元素的删除有明确的函数,所以我们使用以下语法进行切片中元素的删除:
a1 = append(a1[:1],a1[3:]...) //删除切片a1中的第二和三个元素对切片中元素的排序
语法为:
sort.string(s1) //对string类型的切片s1中元素进行排序补充
s2 := strinfs.Sqlit(s1." ") //将s1按照空格进行切片然后赋值给s2指针
n := 1111 //将1111赋值给n这个变量
p =&n //将变量n的地址赋给变量p
m =*p //将变量p所指的内存中的数值赋值给m指针的申请
make函数申请指针
var a=new(int) //申请一个int类型的新的指针,且该指针分配的有内存地址
var a *int //创建了一个int类型的指针,但该指针没有分配内存地址new函数申请指针
make函数相对于new函数来说,它只用于对切片,map,chan进行指针的申请,但make函数比new函数使用的更为广泛
map
map类似于python中的字典,是键和值的组合,通过键来寻找值,这里引用其他人的解释:
Map 是一种无序的键值对的集合。Map 最重要的一点是通过 key 来快速检索数据,key 类似于索引,指向数据的值。
Map 是一种集合,所以我们可以像迭代数组和切片那样迭代它。不过,Map 是无序的,我们无法决定它的返回顺序,这是因为 Map 是使用 hash 表来实现的。map的创建和初始化
var s1 map[string]int
//创建一个名叫s1的map,其中key为string类型,值为int类型,
//注意:一般这样创建的map均没有分配内存地址也就相当于nil为true的状态
s1 =make(map[string]int ,10) //对map s1进行初始化,对其分配的容量大小为10map的赋值
s1["wdnmd"]=18 //表示向map s1中添加一个key为wdnmd值为18的map元素如果访问一个不存在的key,则返回的值为你所定义的map中该类型值所对应的零值
map的删除
语法:
delete(s1,"wdnmd") //表示删除名为s1的map中的wdnmd键同时也会删除该键所对应的值如果删除一个不存在的键值对,最后并不会报错
如果想要删除map中所有的键值对,由于go中没有配置相关的删除函数所以需要我们遍历此map进行逐一删除或者对此map进行重新make初始化,第二种方法原先的map则会被go的gc回收
函数
语法为:
func 函数名(参数名)(返回值){
函数内容
}Go语言中的函数可以有返回值也可没有,参数可以有也可以没有,若有参数则一定要具体规定参数的类型,具体的用法同c语言没有太大的差距
func s1 (x string,y ...int){
fmt.Print(y)
}上边的实例表示函数名为s1的函数能够传入两个参数,其中y可以传入多个值,此时的y的类型为一个切片比如说:
fmt main(){
s1("wdnmd",1,2,3,4,5,6,7)
}此时s1函数中y变量的值为:1 2 3 4 5 6 7,同时y也可以是空值
补充:
unicode.Is(unicode.Han,c) //判断c变量中是否有中文字符defer函数
defer 执行的语句 //defer函数表示在此函数被关闭之前执行被defer的语句如果一个函数中有多个被defer的语句,则执行顺序为先执行最后被defer的语句,最后执行最先被defer的语句。(类似于栈结构),defer函数调用时所用的变量的值已经被固定,后续中该参数值的变化对已经被defer压入栈中的该参数无影响。
字符串后缀比较函数
sstrings.HasSuffix(name, suffix) //判断变量名为name的字符串是否以变量suffix结尾参数和返回值的多样性
fmt s1 (x func() int){
函数体
}
//定义了一个参数为x且x的类型为返回值为int类型的函数的函数fmt s2(x func() int)func(){ 函数体}
//定义了一个参数为x且x的类型为返回值为int类型的函数,函数本身返回值为函数的函数匿名函数
语法为:
var f= func(x, y int){ fmt.Print(x+y)}
//定义了一个匿名函数,并将其返回值赋值给f变量,
//此语法可以用到全局性的函数如果想要调用此函数语法为:f(10,20)如果想要在一个函数中嵌套一个函数则需要用到匿名函数,语法为:
fmt main(){
f1 :=func(x,y int){
fmt.Print(x+y)
}
}
//将函数赋值给一个变量进行使用如果想要进行传参,方法同上或者为:
fmt main(){
func(x,y int){
fmt.Print(x+y)
}(x,y)
}
//此语法中最后括号中的xy为你要传入的参数,同时此语法表示立即执行闭包
我们如果想通过一函数调用另一个函数但因为参数的原因无法实现,此时就需要用到闭包
下面以一个例子来进行具体实验
func main(){
ret := s1(s2 ,100,2000)
ret()
}
func s1(x func(int,int),m,n int)func(){
tmp:=func(){
x(m,n)
}
return tmp
}
func s2(x,y int){
fmt.Println("这是s2")
fmt.Println(x+y)
}闭包相当于把一个函数进行了外包装,在以上代码中从main函数中开始调用了s1函数,根据参数可以看到我们调用了s2函数,同时传入int类型m和n参数,然后在s1函数中声明了一个赋值给tmp的匿名函数用来调用s2函数,并将m和n传入了s2中调用了s2中的语句,接着运行s1中的return将tmp赋值给ret变量,由于ret变量为函数类型,所以需要用函数调用语句来进行调用ret。
结构体
type语句定义自己的类型:
type mystring string
//定义一个新的类型名叫mystring,实际上为string类型类型别名:
type m = int
//想要声明某个变量为int类型,也可以将声明语句定义为:var w y 声明一个int类型的名叫w的变量,
//相当于给int起了个小名,但类型别名仅能生效于代码编译前type person struct{ age int sex string name string}
//定义一个新的类型名为person根本的类型为struct类型也就是结构体类型Go语言中对于一个结构体中的变量名的调用语法为:
person.name="wdnmd"
//将wdnmd赋值给person这个结构体中的name变量总体的语法同c语言相差不大
匿名结构体
语法为:
var s struct{
x int
y string
}
s.x = 18
s.y = "wdnmd"匿名结构体主要用于临时,不建议在函数外单独定义
结构体指针:
var p = new(person) 申请了一个person类型的指针p.x = 18
(*p).x = 18
//以上两个语句所表达的意思均相同,因为p为指针类型,且存储的数据为地址,
//我们在使用p.x=18时Go语言会自动帮我们转义为(*p).x=18声明一个person指针类型的变量f并进行初始化
var f =&person{
name: "wdnmd",
age :"18",
}声明一个person指针类型的变量m并进行初始化,初始化时所附的值一定要与person类型中定义的顺序相同
var m =&person{
"wdnmd",
"18",
}方法
语法为:
func (p person) people() { fmt.Printf("%s:wdnmd", p.name)}方法是作用于特定类型的函数,在以上实例的(p person)中的person表示能够调用当前方法的类型为person类型,p表示一个形参,也就是我们调用person类型时所赋值的变量。
接收器的粗略解释:
接收器可以为任何类型但除了接口类型,它可以是int,string,数组,结构体等,可以理解为特殊类型的变量。
一个类型加上它的方法等价于面向对象中的一个类,一个重要的区别是,在Go语言中,类型的代码和绑定在它上面的方法的代码可以不放置在一起,它们可以存在不同的源文件中,唯一的要求是它们必须是同一个包的。方法的粗略解释:
在go语言中由于结构体的作用类似于面向对象中的类,而在面向对象的语言中普遍的每个类都具有自己的方法,但是go语言中的方法和面向对象中不太一样,它的作用对象为接收器(receiver)就是上边例子中的(p person)这一部分(统称为接收器),也可以理解为方法为一种作用对象为接收器的特殊函数类型。
方法在go语言中大致为分为两类:
一种为传入结构体类型的方法:
这类方法会copy一份我们传入的结构体的数据,但方法中的所有结构体数据的操作不会对原本的结构体中的数据产生任何影响,可理解为我们把原本的结构体中的数据copy了一份到了一个新的结构体中,接下来我们所有的操作都是对这个新结构体的操作,根本原因是我们的所有操作没有修改传入结构体的存储地址中的数据。
一种为传入指针类型的方法:
这类方法会将我们传入结构体的地址传入进来,而我们在方法中对此结构体数据的所有操作都会影响原本的结构体,即我们在此能够对传入结构体的存储地址中数据进行修改。
方法的method value和method expression
method value又名方法值,例子代码为:
package main
import (
"fmt"
)
type person struct {
name string
age int
}
func (p *person) class2(i int) {
fmt.Println("this is a person")
fmt.Println(i)
}
func main() {
var s person
s.class2(3)
p := &person{}
p.age = 10
p.name = "ssss"
p2 := p.class2
p2(1)
}
在这个例子中person为结构体类型的变量,它存在一个方法为class2,如果我们以s.class2(3)这样的方式调用则称其为方法值,方法值相对于接下来的方法表达式来说更简便易懂
method expression又称方法表达式,例子代码为:
package main
import (
"fmt"
)
type person struct {
name string
age int
}
func (p *person) class2(i int) {
fmt.Println("this is a person")
fmt.Println(p.age)
fmt.Println(i)
p.age = 20
fmt.Println(p.age)
}
func (p person) class3(i int) {
fmt.Println("this is a person")
fmt.Println(p.age)
fmt.Println(i)
p.age = 20
fmt.Println(p.age)
}
func main() {
t := person{"www", 10}
t1 := (*person).class2
t2 := (person).class3
t2(t, 15)
t1(&t, 10)
}在此例子中我们可以看到相对于方法值方法表达式在调用相关的方法时多出来了一个参数,这个参数是接收器,再方法值中go的底层对其进行了闭包操作,让接收器这个参数被隐式传入,相对于方法值,方法表达式需要我们在调用方法时需要显式传入接收器,且接收器必须为第一个参数。
结构体的嵌套
我们在使用多个结构体时,会对同一个或者多个变量进行了多次的声明,这时我们可以使用结构体的嵌套,来进行一次声明,多次使用
语法为:
type person struct{
name string
age int
addr address
}
//定义一个person的结构体,调用了address的类型
type company struct{
name string
add address
}
//定义了一个company的结构体,调用了address的类型
type address struct{
province string
city string
}
//定义了一个address的结构体,用于嵌套使用
fmt.main(){
p1 := person{
name:"wdnmd",
age:"18",
addr{
province:"上海"
},
}
fmt.Print(p1)
fmt.Print(p1.addr.province)
}
//定义了一个p1的变量,类型为person类型,其中调用了addr的结构体嵌套匿名嵌套结构体
语法为:
type person struct{
name string
age int
address
}
//定义一个person的结构体,调用了address的类型,其中address类型并没有用变量声明
type company struct{
name string
address
}
//定义了一个company的结构体,调用了address的类型,其中address类型并没有用变量声明
type address struct{
province string
city string
}
//定义了一个address的结构体,用于嵌套使用
fmt.main(){
p1 := person{
name:"wdnmd",
age:"18",
address{
province:"上海"
},
}
fmt.Print(p1)
fmt.Print(p1.province)
}
//定义了一个p1的变量,类型为person类型,
//其中调用了addr的结构体嵌套,可以直接利用语法p1.province来调用province的值结构体中的”继承“
语法为:
type person struct{
age int
name string
string
}
type addr struct{
province string
}
//此时person类型中已经具有了addr类型,
//如果addr类型具有方法函数的话,person中的函数也能够调用addr中的方法函数go语言中对于结构体这样的类继承原理上来讲就是结构体接收任意类型的字段作为嵌入字段,这样在最外边的结构体就具有内部嵌入类型字段的性质,能够调用内部字段的方法,这类似于面向对象语言中的子类与父类的关系。
结构体方法的重写
上边提到了结构体的类似继承,我们可以调用嵌入字段的方法,同样我们也可以对嵌入字段的方法进行重写,类似于面向对象中的对方法的重写,以下是示例代码
package main
import (
"fmt"
)
//父类结构体
type person struct {
name string
age int
}
//子类,嵌套引用了person结构体
type student struct {
person
num int
}
//父类方法(在面向对象语言中来说)
func (p *person) class1() {
fmt.Println("this is a person")
}
//子类方法,对父类方法进行了重写
func (s *student) class1() {
fmt.Println("this is a student")
}
func main() {
var ss student
ss.class1()
}结构体序列化与反序列化
go语言中存在一个名为encoding/json的包能够将结构体中的内容转义为json形式的字符串具体语法为:
package main
import(
"fmt"
"encoding/json"
)
type person struct{
name string
age int
} //创建一个person类型的结构体
func main(){
p1:= person{
name:"wdnmd",
age:18,
} //创建一个名为p1的person类型的变量
b,err:=json.Marshal(p1)
//调用json包中的Marshal函数对变量p1进行编码并将两个返回值分别赋值给b和err,其中err为错误判断的返回值
if err !=nil{
fmt.Print("error")
} //错误判断
fmt.Print(string(b)) //将b进行强制转换为字符串类型并打印
}在上述的示例中,我们到最后只会得到一个{}的结果,或者在我们编译前会在Marshal函数调用p1时提示:struct doesn’t have any exported fields, nor custom marshaling (SA9005)意思是没有导出任何字段,出现这样的错误原因是,Go语言中如果想要让另一个包调用当前包中类型为结构体中已定义的变量类型(类似于上边示例中的name和age两个在结构体中声明过的),就需要将此变量的首字母大写表示此类型相对于当前包来说是公开的,也就说我们在其他包中可以调用此类型的变量中公开的类型,在上边示例中我们只需要把name和age的首字母大写就可以得到结果。
上实例代码逻辑的分析:
定义一个person类型,在main函数中定义了一个person类型的变量p1并对其进行了初始化,然后调用json包中的Marshal函数将p1作为参数传入,会得到两个返回值一个为转义后的字符串,一个为报错判断,接下来用一个if语句进行报错判断,最后将b转换类型为string类型然后打印。
在上边的代码中如果name和age的首字母没有大写那么就表示在当前的包中person类型中的name和age是不公开的,由于不公开我们传入Marshal函数中的值相当于是空,所以返回值也为空,也就导致了最后打印的结果为{},如果将其大写那么表示当前代码中person类型中的name和age对于其他包来说是公开的,是可以被其他包调用的,所以我们此时传入了我们预期的值,最后得到了预期的效果。
如果我们想要让name和age对json这个包公开的为name而不是Name的话具体语法为:
type person struct{
Name string `json:"name" ,db:"name"` //表示如果json或者db包想要调用Name用name代替Name
age int `json:age ,db:age`
}如果我们想要对一个json格式的编码进行反序列化语法为:
str := `{"name":"wdnmd","age":18}`
var p2 person
json.Unmarshal([]byte(str),&p2)
fmt.Print(p2)以上示例中Unmarshal函数用法为将str变量进行强制转换然后将转换后的值,传给p2,而传指针是为在Unmarshal函数中修改p2的值
结构体示例简单的学生信息管理系统
main.go内容如下:
package main
import (
"fmt"
)
var smr studentMan
func menu() {
fmt.Println("1.增加学生信息")
fmt.Println("2.查看所有学生信息")
fmt.Println("3.删除学生信息")
fmt.Println("4.修改学生信息")
fmt.Print("你的选择:")
}
func main() {
smr = studentMan{
allstudent: make(map[int64]*student, 100),
}
for {
menu()
var chioce int
fmt.Scanln(&chioce)
switch chioce {
case 1:
smr.addstudent()
case 2:
smr.showstudent()
case 3:
smr.deletestudent()
case 4:
smr.editstudent()
default:
fmt.Println("请重新输入")
}
}
}
student.go内容如下:
package main
import (
"fmt"
)
type student struct {
id int64
name string
}
type studentMan struct {
allstudent map[int64]*student
}
func (s studentMan) addstudent() {
var (
Id int64
name string
)
fmt.Print("请输入学号:")
fmt.Scanln(&Id)
fmt.Print("请输入姓名:")
fmt.Scanln(&name)
strnew := newstudent(Id, name)
smr.allstudent[Id] = strnew
}
func newstudent(id int64, name string) *student {
return &student{
id: id,
name: name,
}
}
func (s studentMan) showstudent() {
for _, v := range s.allstudent {
fmt.Printf("学号:%d 姓名:%s\n", v.id, v.name)
}
}
func (s studentMan) deletestudent() {
fmt.Println("输入删除学生学号")
var card int64
fmt.Printf("学号:")
fmt.Scanln(&card)
delete(smr.allstudent, card)
}
func (s studentMan) editstudent() {
var (
stuid int64
name string
)
fmt.Print("请输入需要修改的学生学号:")
fmt.Scanln(&stuid)
fmt.Printf("学生姓名:")
fmt.Scanln(&name)
strnew := newstudent(stuid, name)
smr.allstudent[stuid] = strnew
}
接口
接口的定义
接口为一种类型,在此类型中,可以存在有多个方法,如果实现了此接口内部的所有方法表示实现了此接口,但是go语言的接口实现并不是像java中那样的显式实现(需要在我们自己所写的的代码中进行声明),它会是隐式的实现,下边举个例子:(此例子为部分代码)
type Duck interface {
Quack()
}
type Cat struct{}
func (c Cat) Quack() {
fmt.Println("meow")
}在上边的例子中我们可以看到我们在cat的方法中压根就有看到Duck的影子,但我们可以说是Cat结构体实现了Duck这个方法,这和著名的鸭子模型很像,鸭子模型的表述为:
当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子 --引自维基百科同样的我们在这里说我实现了你这个接口所有的方法,那么我就实现了你这个接口,类比一下我实现了这个接口的所有方法相当于我具有一只鸭子的已确定的我们当前定义鸭子的所有特征,而实现这个接口相当于我就是一只鸭子。
在go语言中如果我实现了你这个接口的所有方法,那么我就隐式的实现了你这个接口,注意这里是隐式的实现,如果只看上边的代码,很多人会以为我确实是实现了Duck这个结构,但是还是会感觉我在程序运行时并没有实现这个接口,
package main
import (
"fmt"
"reflect"
)
type Duck interface {
Quack()
}
type Cat struct{}
func (c Cat) Quack() {
fmt.Println("meow")
}
func main() {
var c Cat
fmt.Println(reflect.TypeOf(c))
c.Quack()
}实际上我们如果按照上边的示例执行的话在编辑器中也确实会出现会出现Duck未被使用,但是go程序运行时并没有爆出相关的错误,要知道go对于定义未使用的变量这些要求是很严格的,实际上我们此程序运行时,编译器会隐式的将我们的c.Quack转换为Duck类型从而实现,所以我在上边强调了隐式。
再来说一下接口的具体类型,我们知道go语言和python,PHP这些语言不一样,它是静态语言,这也就导致了我们对一个变量的类型,如果不对其进行类型的强制转换变量的类型在整个程序运行的过程中是不会发生转换的,如果我们定义了一个interface类型的变量其类型判断输出会是nil,而为什么会是nil,接口类型的静态类型就是它本身也就是interface,但是接口本身没有专属于自己的静态值,它的静态值指向的是传入的动态值,而这个动态值会在接下来进行解释
接口按照底层构造不同细分为两种类型,一种为所定义的内部具有具体方法的接口(iface),一种为空接口(接口里边啥都没有)(eface),这两种接口的底层不完全一样,
eface的底层具体由_type类型的指针和unsafe.Pointer类型的变量data
type eface struct { // 16 字节
_type *_type
data unsafe.Pointer
}而对于iface的底层代码为:
type iface struct { // 16 字节
tab *itab
data unsafe.Pointer
}这两个接口的type字段不太相同,由于go语言的这类类似函数的传值都是只拷贝传入元数据的副本,所以两个接口类型的data字段所指向的都是传入接口的数据的副本
在空接口的底层组成中的type指针所指的是一个type类型的结构体,此结构体的大致组成为:
type _type struct {
size uintptr
ptrdata uintptr
hash uint32
tflag tflag
align uint8
fieldAlign uint8
kind uint8
equal func(unsafe.Pointer, unsafe.Pointer) bool
gcdata *byte
str nameOff
ptrToThis typeOff
}size 变量主要是存储此类型所占用的空间大小,hash字段是为判断类型的是否相等,目前我所了解的就只有这么多
对于非空接口的内部组成的itab类型的结构体其组成大致为:
inter *interfacetype
_type *_type
hash uint32
_ [4]byte
fun [1]uintptr其中inter这个interface指针类型的变量存储的是当前interface的静态类型也就是interface,而下边的type存储的是在利用此接口时所传进来的变量的具体类型信息,hash字段存储的是传入值相关类型的hash值(和type字段中的hash值一致),func则存储的是具体的方法函数的地址,看起来它只有一个长度,如果遇到多个方法可以利用指针偏移进行相关方法的寻找。
类型转换
我们都知道接口这个东西你如果实现了它那么它就会被显式或者隐式的实现,所以现在来说一下我们具体是如何实现接口的(由于本人实在不会汇编这里只能简单说一下)
方法为指针类型的转换
大致的流程为:先对此结构体进行初始化,然后将其转换为接口类型,然后调用接口方法(感觉和把大象放进冰箱的本质一样)
那么对于结构体类型的指针的初始化的流程为
1.将结构体类型指针入栈,注意是类型指针(也就是_type)
2.然后调用runtime.newobject这个函数,参数为我们传入的结构体指针,函数的返回值为为我们的结构体分配的内存的指针此返回值会在SP+8这个位置(SP: 栈顶,栈帧的结束位置),然后把栈上的指针拷贝到寄存器 DI 上方便操作(这一步不太理解),然后就是对结构体长度的判断和数据存储。
简单点来说就是我们先把结构体类型的指针放在一个空间有限的临时空间中,这时候我们肯定不能把这个指针长时间放在这,所以就调用一个函数给这个指针所指的结构体分配存储空间,然后就是把数据往里边存储。
以上为结构体的初始化过程那么转换类型,具体是怎么转换为接口类型的大致流程为:
由于我们在SP上存储了传入的结构体类型指针,这与接口中那个type是一样的,那么我们可以利用相关函数,将此copy到interface类型的type类型中,然后再利用汇编语言生成一个完整的itab类型的结构体,接着是数据部分,就是将原来结构体存储空间的地址赋值给data字段。
我们如果在最后看到方法的真正执行结果会发现最后的执行函数是我们的结构体外加方法,而不是接口名加方法,这是因为go语言的编译器在调用相关方法期间会将方法的动态调用改为对目标方法的静态调用,主要是为了节省性能。(这段我抄的)
对于方法的结构体的初始化的过程为:
具体过程和上边的相差不大,但毕竟是传入的结构体类型还是会有差别
首先先是接受对应的结构体并将结构体数据存储到内存中,接下来会调用runtime.convTstring这个函数会将我们结构体存储的数据传入然后返回一个unsafe.Pointer类型的返回值,这个值是不是很眼熟,就是接口类型结构体的数据部分,然后我们会和上边的指针类型相似会根据传入的结构体类型构造itab类型的结构体。
定义一个接口,语法为:
type speaker interface //定义一个名为speaker的接口类型定义一个传入参数为接口类型的函数:
func wdnmd(x interface){
x.speaker()
}
//此函数传入的参数不会管你传入的参数是什么,唯一关心的是你传入的参数中是否含有speaker这个方法如果我们定义了一个接口类型的变量s,定义一个person类型的变量a(person是我们自己定义的一个结构体类型),然后传入参数给此变量,然后我们会发现变量s的类型会变为person,这是因为接口为了实现对不同类型的传入变量进行统一进行方法的运算,在定义一个接口类型的变量时,变量的动态类型和动态值均为nil,在上述例子中变量s的初始类型和初始值均为nil,我们在传入变量a的同时也将变量a的类型传入了进去,让s变量的动态类型为person动态值为a的值。
类型断言
在上边的过程都为其他类型转换为接口类型,那么由接口类型转换为其他类型的过程是怎么转换的(实际上底层还是接口类型),接下来会进行粗略的讲解。
类型断言(Type Assertion)是一个使用在接口值上的操作,用于检查接口类型变量所持有的值是否实现了期望的接口或者具体的类型。 ————引自c语言中文网注意以上的定义中是接口值的操作,也就是我们动态的传入接口的东西
非空接口的类型断言
具体例子如下:
package main
import "fmt"
type wdnmd interface {
Select()
}
type person struct {
name string
}
func (p *person) Select() {
fmt.Println("wdnmd")
}
func main(){
var c wdnmd = &person{name: "wwww"}
v, ok := c.(wdnmd)
if !ok {
fmt.Printf("%v\n", v)
}
fmt.Printf("%T\n",c)
c.Select()
}我们在main函数中定义了一个wdnmd类型的变量c同时也给它复制成了person结构体的指针,而我们的输出结果为c为person类型的指针,这其中就用到了类型断言。用到类型断言的部分为:
v, ok := c.(wdnmd)
基本原理为:检查c的底层类型是否为我们所定义的wdnmd类型,如果是返回true并将值赋值给v,如果不是则会出现panic
具体的实现过程如下:
(这里我暂时还有疑问就是这里的参数中的inter参数是谁的inter)
前半部分的过程为接收传入的值类型并生成相关的iftab结构体(同上边的方法为指针的类型转换的过程相似),不同的是,我们在生成相关的itab结构体和数据的指针后会调用一个函数runtime.assertI2I2(),这个函数主要作用就是用来做检测的,它传入的参数为inter interfacetype, i iface,前一个为我们非空接口中那个inter字段,然后iface由于它是由itab和data两部分组成,所以实际上我们是传入三个参数 * interfacetype, itab,data,然后此函数的具体代码如下:
func assertI2I2(inter *interfacetype, i iface) (r iface, b bool) {
tab := i.tab
if tab == nil {
return
}
if tab.inter != inter {
tab = getitab(inter, tab._type, true)
if tab == nil {
return
}
}
r.tab = tab
r.data = i.data
b = true
return
}//我从go的github官方抄的先是做了tab的为nil判断,然后是inter类型的相等判断,如果不相等再利用getitea函数根据传入的inter和tab中type进行新生成一个tab,然后就是赋值返回了,另外我在另一篇文章里看到了另外一种的判断方法是根据tab中的hash值同特定的hash值进行判断(感觉是以前的go版本的判断方法)
然后就是将此函数的返回值赋值给我们上边自己定义的v和ok,这里我感觉其实真正重要的是itab中inter的对比,因为类型断言要得就是你最底层的类型比对结果。
至于类型查询(type switch)和动态派发,直接放弃了,属实是难顶。
接下来是空接口的类型断言(这里我有没有看懂的地方,如果不对欢迎指出)
例子如下:
package main
import "fmt"
type wdnmd interface {
Select()
}
type sss interface {
}
type person struct {
name string
}
func (p *person) Select() {
fmt.Println("wdnmd")
}
func main(){
var c wdnmd = &person{name: "wwww"}
var a sss = person{name:"ssss"}
fmt.Printf("%T\n",a)
s,ok := a.(person)
if !ok {
fmt.Println("wdnmdssss",s)
}
v, ok := c.(sss)
if !ok {
fmt.Println("wdnmdaaaa",v)
}
fmt.Printf("%T\n",c)
c.Select()
}
空接口的类型断言大致比较原理是将目标类型的*type和空接口中的 *_type进行对比,相同返回true和对应的值,失败则会返回false出现panic,我这里就产生了一个疑问就是,如果我类型断言的不是person而是sss他确实会发生变化,但是我感觉此时空接口的type字段存储的应该是person的类型hash那么这是如何比较的呢?,在上边的非空接口也有类似这样的疑问,具体是我如果类型断言的对象不是person而是非空接口,比对过程又是怎么样的呢?
值接收者和指针接收者
结构体的方法参数分为值接收和指针接收,两者的区别为:
值接收者能够接收指针和数据类型,而指针接收者只能接收指针。代码层面最根本的差别是方法传入参数的差别,在平常的使用中最常见的是指针接收者
如果想要对一个结构体实现多个接口,只需定义不同的方法再分别用不同的接口函数进行调用就可实现一个结构体对应多个接口。同时,接口之间可以进行嵌套,示例:
type s interface{
mover
driver
}
//定义了名为s的一个接口,内部调用了其它接口
type mover interface{
move()
}
//定义了一个名为mover的接口,内部调用了move方法
type driver interface{
drive()
}
//定义了一个名为driver的接口,内部调用了drive方法空接口
空接口表示为能够接收任何类型的变量,因为空接口内部没有对方法进行限制,也就意味着任何结构体都能够实现这个接口,语法为:
interface{}
//定义了一个空接口空接口与map的组合:
var s1 = map[string]interface{}
//定义了一个名为s1的map类型的变量,其中key的类型为string,value的类型为interface 包(package)
Go 语言的源码复用建立在包(package)基础之上。Go 语言的入口 main() 函数所在的包(package)叫 main,main 包想要引用别的代码,必须同样以包的方式进行引用,本章内容将详细讲解如何导出包的内容及如何导入其他包。 ——引自他人解释
定义一个包名:
package 包名 在同一文件夹下只能有一个main包,同时所有的也只能有一个main函数,Go语言程序是以你的main包中的main函数作为入口开始运行的。
导入包:
import "包的位置"
//包的位置默认是从GOPATH下的src文件开始一级一级的往下找包的所在位置注意:
在调用的包中,如果我们想要调用包中的某一个函数则需要将函数的首字母大写表示此函数是公开的。
Go语言中禁止循环导入包,两个包之间禁止互相导入。
匿名导入包
import _"包的位置"
//表示匿名导入包,相当于导入了这个包但没有使用这个包中的任何方法init函数
func init(){
语法
}
//表示在调用这个包时就会自动调用这个函数中的内容init函数不能主动调用,同时init函数没有参数和返回值,只能在程序运行时自动调用
函数执行顺序:
全局变量的声明—>init函数执行—>main函数执行
如果一个main包调用了a包,a包中调用了b包,那么我们执行顺序则为:
全局变量的声明—>b包init函数执行—>a包init函数执行—>main包init函数执行
time包
time包主要用于读取当前的时间
now := time.Now()
fmt.Println(now.Day()) //输出当前是几号
fmt.Println(now.Year()) //输出当前是几年
fmt.Println(now.Minute())//输出当前是几分
fmt.Println(now.Second())//输出当前是几秒
fmt.Println(now.Unix())//获取时间戳now := time.Unix(时间戳,标志位) //将时间戳转换为标准的时间格式时间的加减:
fmt.Println(now.Add(24 * time.Hour))//加24小时
//时间相减
td := timeobj.Sub(now)
//将timeobj和now相减(now-timeobj)最后得到一个时间间隔类型的数据赋值给td变量计时器:
wd := time.Tick(time.Second)
//将按秒读取的时间赋值给wd变量
for wt := range wd {
fmt.Println(wt)
}
//循环输出时间时间格式化:
now := time.Now()
fmt.Println(now.Format("2006-01-02 15:04:05"))
//输出结果为:2021-06-04 11:29:45将字符串转换为时间戳:
Te,err := time.Parse("2006-01-02" ,"2021-06-04")
if err !=nil{
fmt.Println("error")
}
fmt.Println(Te)
//以2006-01-02的格式输出2021-06-04的时间
fmt.Println(Te.Unix())
//输出时间戳输出东八区的时间
loc, err := time.LoadLocation("Asia/Shanghai")
if err != nil {
fmt.Println("error")
}
timeobj, err := time.ParseInLocation("2006-01-02 15:04:05", "2021-06-04 12:06:40", loc)
if err != nil {
fmt.Println("error")
}
fmt.Println(timeobj)runtime包
Caller函数
pc,file,line,ok:=runtime.Caller(1)
//pc为uintptr类型的变量
//file为文件的绝对路径
//line表示在第几行代码处调用了这个函数
//ok为报错信息文件读取
文件读取需要用到一个名为os的包,其中包含了打开文件的函数和读取文件的函数
func main(){
file,err := os.Open("./main.go")
if err !=nil {
fmt.Println("error")
return
}
defer file.Close()
var tmp [512]byte
n,err := file.Read(tmp[:])
if err != nil {
fmt.Print("error")
return
}
fmt.Println(string(tmp[:n]))
}以上例子为打开当前目录下的mian.go文件并读取,其中os.Open函数为打开文件的函数,用法为os.Open(“相对路径”),此函数会返回两个返回值其中file接收的是一个*file类型的返回值,err接收的是错误的返回值。
file.Close()函数为关闭读取文件的函数,通常会与defer一起运用
file.Read()函数
file.Read()函数为读取文件的函数它实际上是一个方法,具体为:
func (f *file)Read(b []byte)(n int,err error)传入的参数为byte类型,visual code的介绍为:
Read reads up to len(b) bytes from the File. It returns the number of bytes read and any error encountered. At end of file, Read returns 0, io.EOF.
意思为:
Read从文件读取最多len(b)个字节。它返回读取的字节数和遇到的任何错误。文件结束时,Read返回0,io.EOF。
此时它会将读取的内容存储到tmp这个byte类型的数组中,而这个函数的返回值n表示此次读了多少个字节。
bufio.NewReader()函数
此函数与上边的file.Read函数一样输一个读取函数具体用法为:
reader := bufio.NewReader(file)//接收一个os.Open函数的*file的返回值file
for {
fileread, err := reader.ReadString('\n')
//读到\n第一次出现为止
if err == io.EOF {
return
}
if err != nil {
fmt.Println("error")
}
fmt.Print(fileread)
}
//循环按行读取iout.ReadFile函数
此函数遇上一个函数作用相同都是打印读取的内容,不过此函数打印的是完整的文件内容
func read3() {
file, err := ioutil.ReadFile("./main.go")
//返回一个字节类型的数据和一个error类型的数据
if err != nil {
fmt.Println("error")
return
}
fmt.Println(string(file))
}文件的写入
os.OpenFile()函数
os.OpenFile()函数能够以特定形式打开一个文件,从而达到写入文件的效果
func Openfile(name string,flag int,perm Filemode)(*File,error){
}
//函数参数和返回值name为打开的文件名字,perm filemode表示权限,实际上表示在Linux系统中是以怎样的权限打开文件,flag表示为以怎样的方式打开文件,常见flag的参数为:
- O_RDONLY:只读模式打开文件;
- O_WRONLY:只写模式打开文件;
- O_RDWR:读写模式打开文件;
- O_APPEND:写操作时将数据附加到文件尾部(追加);
- O_CREATE:如果不存在将创建一个新文件;
- O_EXCL:和 O_CREATE 配合使用,文件必须不存在,否则返回一个错误;
- O_SYNC:当进行一系列写操作时,每次都要等待上次的 I/O 操作完成再进行;
- O_TRUNC:如果可能,在打开时清空文件。
如果想要同时使用写和读只需要对flag参数进行逻辑异或运算,flag的常见参数为16进制的数我们在进行逻辑异或运算后得到是一个二进制的数,而flag的检查则为在某一个位置上的数字是否为1,为1的话表示执行这个操作。
write函数和writestring函数
两个函数均为向文件中写入,
write函数的用法为:
file.Write([]byte("wdnmd"))
//write函数为*os.file的方法,传入的参数类型需要为[]byte类型writestring函数的用法为:
file.writestring("wdnmd")
//writestring函数相对于write函数来说并没有参数的限制bufioNewWriter函数
此函数同上边两个函数作用相同也是向文件中写入
wd := bufio.NewWriter(file)
//接收一个file(上边OpenFile函数返回的*file)
wd.WriteString("wdnmd")
//写入缓存
wd.Flush()
//从缓存中向文件写入ioutil.WriteFile函数
此函数同以上函数的作用相同,向文件中写入,语法为
str := "wdnmd"
//将需要写入的内容赋值给一个字符串
err := ioutil.WriteFile("./wdnmd.txt", []byte(str), 7777)
//此函数有三个参数,第一个为需要打开的文件名,第二个为写入的类型,第三个为权限kind和type
在go语言中类型的划分为两种,一种是kind;一种是type;type指的是当前的表层类型,而kind指的是最底层的种类,举一个例子
package main
import (
"fmt"
"reflect"
)
type person struct {
}
//定义一个person类型的结构体
func typeof(t interface{}) {
x := reflect.TypeOf(t)
//判断传入空接口的数据类型
fmt.Println(x)
//输出该数据的type类型
fmt.Println(x.Kind())
//输出该数据的kind类型
}
func main() {
var b person
typeof(b)
}这个例子的输出为:
main.person
structtype输出的是我们自己所定义的一个person类型,虽然我们知道它本质上是结构体类型,但type识别为person类型,而kind会识别你你传入t这个空接口最本质的类型:结构体类型。
反射
引用(虽然我也看不太懂):
在计算机科学中,反射是指计算机程序在运行时(Run time)可以访问、检测和修改它本身状态或行为的一种能力。用比喻来说,反射就是程序在运行的时候能够“观察”并且修改自己的行为。目前我已知能够用到反射的场景为传入函数的参数为一个空接口类型,由于空接口类型能够传入所有类型所有值,所以有时后需要我们对传入的数据进行类型和值得判断。
kind和type
在go语言中类型的划分为两种,一种是kind;一种是type;type指的是当前的表层类型,而kind指的是最底层的种类,举一个例子
package main
import (
"fmt"
"reflect"
)
type person struct {
}
//定义一个person类型的结构体
func typeof(t interface{}) {
x := reflect.TypeOf(t)
//判断传入空接口的数据类型
fmt.Println(x)
//输出该数据的type类型
fmt.Println(x.Kind())
//输出该数据的kind类型
}
func main() {
var b person
typeof(b)
}这个例子的输出为:
main.person
structtype输出的是我们自己所定义的一个person类型,虽然我们知道它本质上是结构体类型,但type识别为person类型,而kind会识别你你传入t这个空接口最本质的类型:结构体类型。
对反射的数据进行值的修改
由于我们向一个函数传入参数,如果对该值进行了修改,只会修改它的副本,不会修改它内存地址上所存储的值,所以我们如果想要对反射的值进行修改就需要传入一个指针,达到修改内存地址所存储的值得目的。
package main
import (
"fmt"
"reflect"
)
func reflectvalue(x interface{}) {
v := reflect.ValueOf(x)
//判断传入的数据类型
if v.Elem().Kind() == reflect.Int64 {
v.Elem().SetInt(200)
}
//利用elem方法来获取指针所对应的值
//利用setint函数修改该指针所存储的数据
}
func main() {
var s int64 = 100
reflectvalue(&s)
fmt.Println(s)
}go语言的并发和并行
并发的定义:
同一时间段内同一个源执行多个任务(说通俗点就是在同一时间段内你同时和两个女朋友聊天(我没有女朋友-.-))
并行的定义:
同一时刻执行多个任务(你和你朋友都在和女朋友用微信聊天)
go语言中通过goroutine来实现并发,例子如下:
package main
import (
"fmt"
"time"
)
func hello() {
fmt.Println("hello world")
}
func main() {
go hello()
fmt.Println("wdnmd")
time.Sleep(time.Second)
}go语言中在要执行的语句前加go表示创建一个进程来执行此语句也就是上述例子中的go hello(),至于为什么要sleep是因为我们是在main这个函数下创建的线程,而main函数只有两句话就结束了随之的main函数启动的goroutine也就结束了,如果我们不加sleep函数则会导致go hello()这个线程刚创建就结束了(还没开始就结束了),所以需要用sleep等待go hello()这个goroutine运行。
for循环和goroutine的组合
package main
import (
"fmt"
"time"
)
func main() {
for i := 0; i <= 100; i++ {
go func() {
fmt.Println(i)
}()
}
fmt.Println("wdnmd")
time.Sleep(time.Second)
}在运行上边的例子时我们会发现输出结果有很多的重复,原因是我们在一次for循环时创建了一个gotoutine这时会请求i的值由于我们并没有将i作为参数传入函数所以会向上一级请求i的值然后输出,但是,for循环不会等我这个goroutine运行完再进行下一次循环,所以我们就请求了很多相同的值,优化过后的代码为:
package main
import (
"fmt"
"time"
)
func main() {
for i := 0; i <= 100; i++ {
go func(i int) {
fmt.Println(i)
}(i)
}
fmt.Println("wdnmd")
time.Sleep(time.Second)
}此时我们把i作为匿名函数的参数进行goroutine输出,此时由于i已经是创建线程时的参数,与for循环是否顺利进行无关了,不需要再向上一级请求i的值,所以就打印完全了,至于为什么打印出的值无序是因为有些进程先完成打印,有些晚完成。
sync.WaitGroup的使用
代码:
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
//定义一个名为wg的变量类型为WaitGroup
func f1(a int) {
defer wg.Done()
//进程结束wg减一
fmt.Println(a)
}
func main() {
for i := 0; i <= 100; i++ {
wg.Add(1)
//每开一个进程就将wg加一
go f1(i)
}
wg.Wait()
//等待wg减为0,如果没有上方的wg.Done语句则会出现报错
}
在上边我们用time.Sleep来等待进程结束但这样有时候无法确认需要sleep的时间所以利用sync.WaitGroup来判断一个线程的是否关闭
channel
“不要通过共享内存来通信,而应该通过通信来共享内存”这是引自golang社区的经典语句,
在上边简单说明了多线程,而如果我们利用goroutine实现了一个函数,同时也利用goroutine实现了另一个函数,如果这两个goroutine之间需要进行数据交互,就需要用到channel这一类型,而channel表示的是创建一个通道,不同于其他语言的通过改变一个全局变量的值来实现不同线程之间的共享内存来通信,go语言采用的是将两个线程之间连接通道的通过通信来共享内存。
channel采用的是队列的方式进行数据的传输,也就是先进先出
var a chan int //定义一个int类型的channel
a =make(chan int)//对channel进行初始化且没有分配缓冲区
a =make(chan int,10)//对channel进行初始化并分配了大小为10的缓冲区通道类型定义之后就只能传该类型的数据,且在定义channel之后一定要进行初始化。
ch <- 10 //向通道中发送10
x:= <-ch //从通道中接收值并赋值给x
<-ch //从通道中接收值但忽略
close(ch) //关闭通道一个简单的子域名扫描器:
package main
import (
"bufio"
"fmt"
"io"
"net/http"
"os"
"strings"
"sync"
)
var ch chan string
var final chan string
var wg sync.WaitGroup
func request(ch <-chan string, final chan<- string) {
defer wg.Done()
for a := range ch {
resp, er := http.Get(a)
if er != nil {
fmt.Printf("%s 请求失败\n", a)
continue
}
//defer resp.Body.Close()
if resp.StatusCode == 200 {
fmt.Println(a, "200 ok")
final <- a
}
}
}
func result(ch chan string) {
defer wg.Done()
file, err := os.OpenFile("./final.txt", os.O_TRUNC|os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0644)
if err != nil {
fmt.Println("error")
fmt.Println(err)
return
}
defer file.Close()
for a := range ch {
s := a + " " + "\n"
file.WriteString(s)
}
}
func read(s string, ch chan<- string) {
defer wg.Done()
file, err := os.Open("./domain.txt")
if err != nil {
fmt.Println("error,请检查错误")
}
defer file.Close()
reader := bufio.NewReader(file)
for {
str, _, err := reader.ReadLine()
if err == io.EOF {
return
}
string := string(str)
a := "http://" + string + "." + s
a = strings.Replace(a, " ", "", -1)
ch <- a
}
}
func main() {
var s string
fmt.Print("请输入域名:")
fmt.Scanln(&s)
ch = make(chan string, 16)
final = make(chan string, 16)
go read(s, ch)
for i := 0; i < 5; i++ {
go request(ch, final)
wg.Add(1)
}
go result(final)
wg.Add(2)
wg.Wait()
}channel中的select
具体的语句为:
select {
case 执行语句:
case 执行语句:
}例子为:
package main
import (
"fmt"
)
var inc chan int
func main() {
inc = make(chan int, 10)
var num int
for i := 0; i < 10; i++ {
select {
case num = <-inc://从通道中读取值赋值给num
fmt.Println(num)
case inc <- i://向通道中写入i这个变量
}
}
}以上例子中两个case语句在每一次执行时会随机选择一个执行,若有一个无法执行就执行另一个,若都无法执行,则会执行default语句(这里我没有写),以上例子的结果是随机的,如果把通道的make大小改为1则结果为:0 2 4 6 8。
锁
互斥锁
我们在进行异步操作时,对同一个数据会出现两个子线程同时修改的情况,这样就需要利用互斥锁来进行对数据的加锁以便实现操作
package main
import (
"fmt"
"sync"
)
var x = 0
var wg sync.WaitGroup
func add() {
for i := 0; i < 10000; i++ {
x = x + 1
}
wg.Done()
}
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x)
}在以上的例子中,会出最后得到的结果不为20000,出现这样的原因为我们开了两个线程来对x实习操作,有时候会出现两个同时对它进行操作,如果想要避免这种情况则需要在每个线程对x进行操作的时候加上互斥锁。
互斥锁的语法为:
var lock sync.Mutex //定义一个全局的名为lock的互斥锁如果将其用在以上的例子中代码为:
package main
import (
"fmt"
"sync"
)
var x = 0
var wg sync.WaitGroup
func add() {
for i := 0; i < 10000; i++ {
lock.Lock()
x = x + 1
lock.Unlock()
}
wg.Done()
}
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x)
}读写锁
上边的互斥锁对于单一操作来说能够保证数据的正确性,如果们在这其中再加入读的操作,如果一个数据发生变化,则所有的读操作都要等待操作完成,所以为了提高效率,就有了读写锁,及读写分离。
代码为:
package main
import (
"fmt"
"sync"
"time"
)
var x = 0
var wg sync.WaitGroup
var rw sync.RWMutex //定义一个读写锁
//读的函数
func write() {
defer wg.Done()
rw.RLock()//读锁
fmt.Println(x)
rw.RUnlock()
}
//写的函数
func add() {
defer wg.Done()
rw.Lock()//写锁
x = x + 1
rw.Unlock()
}
func main() {
for i := 0; i < 1000; i++ {
go add()
wg.Add(1)
}
//睡眠1秒为了方便等待写操作的完成,若不等待则最后的结果会有一定的随机性
time.Sleep(time.Second)
for i := 0; i < 10; i++ {
go write()
wg.Add(1)
}
wg.Wait()
}
sync补充
sync中的once
sync中的once表示某一操作只执行一次,once中含有一个结构体,结构体中含有锁和标志位,标志位表示此操作是否执行过,若为执行过则先改变标志位,在进行加锁然后执行后解锁。
执行代码为:
//once传入的参数必须为没有参数和返回值的函数类型,所以有些时候需要用到闭包
once.DO(语句)sync中的sync.Map
在上边我们学过map这一类型,如果我们i用goroutine对map进行多线程赋值,go语言一般来说最多只支持20个,如果想要赋值更多则会报错,在实际中如果想要对map进行多个赋值则需要利用sync.Map进行实现。例子为:
package main
import (
"fmt"
"strconv"
"sync"
)
var wg sync.WaitGroup
var m sync.Map//定义一个名为m的sync.map类型的变量
func m_ap() {
for i := 0; i < 100; i++ {
wg.Add(1)
go func(n int) {
key := strconv.Itoa(n)
//利用sync.Map内置的函数对map进行键值对的赋值,且赋值只能用此函数
m.Store(key, n)
//利用sync.Map中的内置函数Load对map及进行取值,且取值只能用此函数
value, _ := m.Load(key)
fmt.Println(key, value)
wg.Done()
}(i)
}
}
func main() {
m_ap()
wg.Wait()
}
